POSTS
Third Chipy Post
Last post I left off on getting the neighborhood regions and grocery markers on the map. This month was largely spent on getting the data set up for food desert calculations. I spent a bit of time on the theoretical aspect to create the algorithm. However, in practice doing a step like projections to XY coordinates took a long time.
This blog post, I’m breaking down the methodology/theory of determining a food desert region and then I will be discussing the progress in my application.
Theory
Spatial analysis is the analysis of “topological, geometric, or geographic properties.” Another important piece of information is that spatial analysis consists of many approximations due to the complex nature of space and the physical earth. This is known as spatial heterogeneity which is the “distinct uniqueness of each region.”
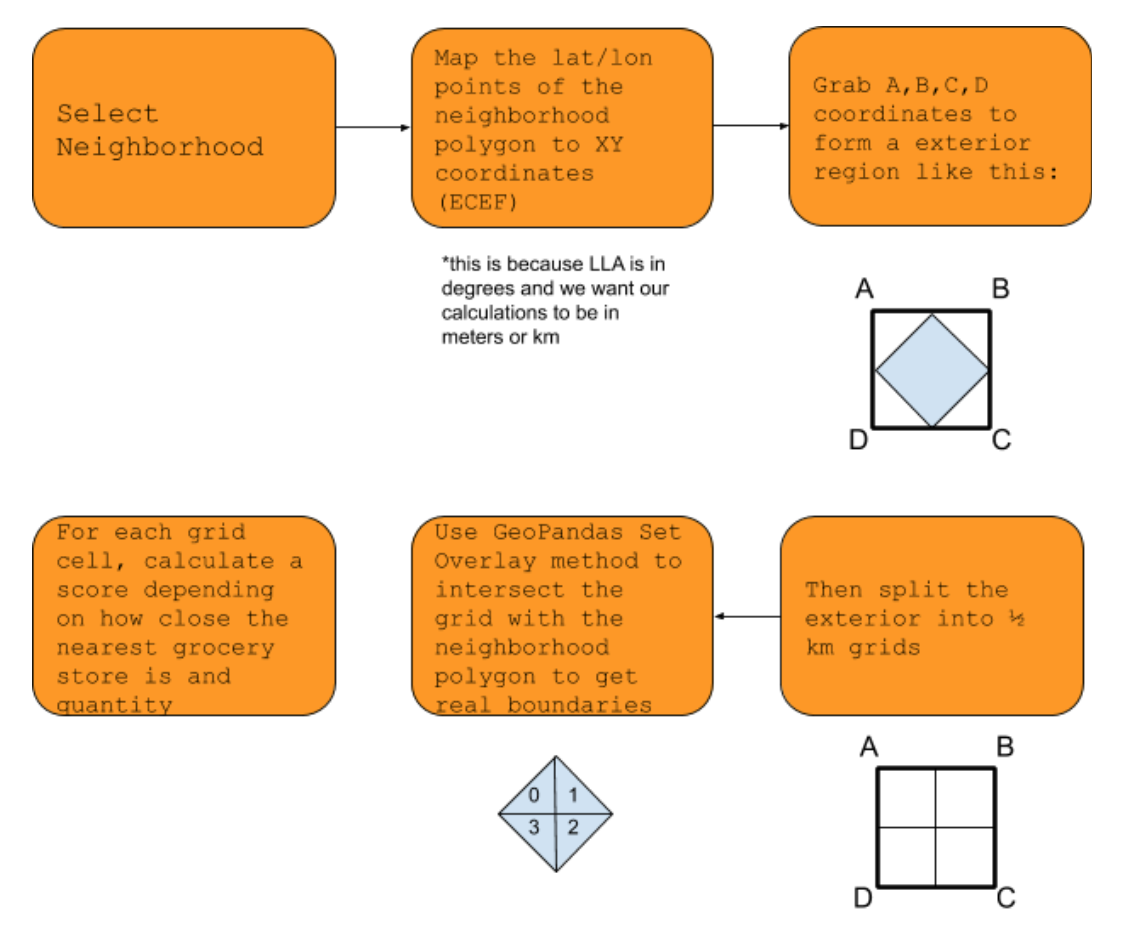
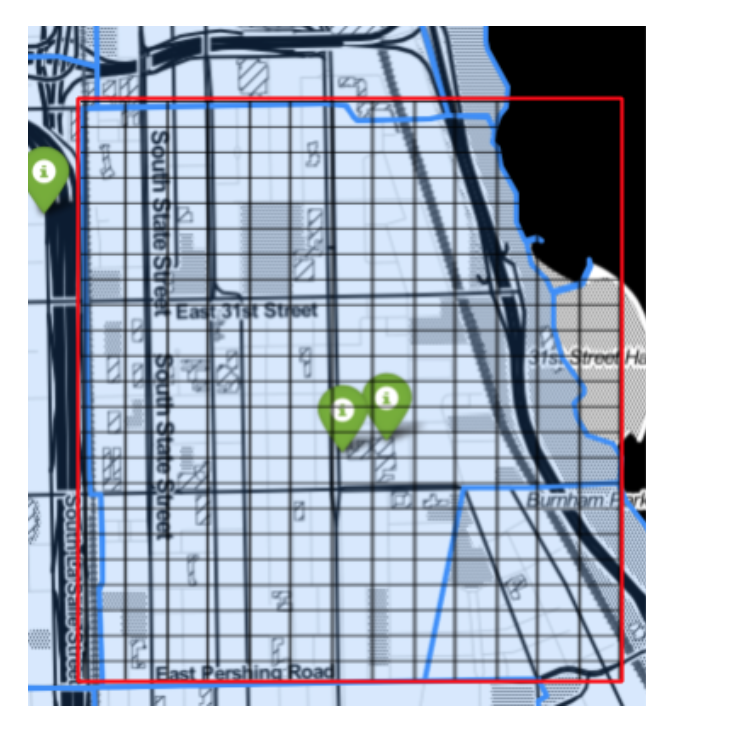
For my project I will be using spatial sampling. This is using observations in one region to “predict” the value of another as an approximation technique. Classifying food deserts means whether a region has accessible grocery options. To reduce a region to a point means that there would be almost an infinite amount of calculations. To approximate I will be dividing a region (going by each neighborhood) into grid cells that are ½ km^2 and calculating distances from the centroid of that grid. The challenges of this approach will be discussed in a subsequent paragraph.
After the grids have been designated a health score from 1-10, which for now a ten is having one grocery store within a 0.5 mile distance. I will be using Manhattan distance over a Euclidean distance because you can’t necessarily travel in a straight line to get somewhere because of the road network. After scores have been calculated for each grid cell, we will use aggregation with dissolve so that before we zoom we can judge the health of a specific neighborhood. This method is built in to the GeoPandas Library.
Before I started coding, I knew there was a minor kink in the theory for grids by neighborhood. If neighborhoods look like this:
Then after a grid is approximated, some of those grids are cut off by the boundary of the neighborhood. To work around this Geopandas has a set overlay method where you can do a set intersect between two polygon series. From here, it becomes a bit easier because there is an existing method to calculate the centroid of any GeoPandas polygon which can be used to calculate the distance between grocery stores.
Code
pdb is Python’s debugger. My mentor, Kevin taught me how to use it and it has now become an essential in my coding toolkit.
import pdb
# lines of code
pdb.set_trace()
# problematic code
This can allow you to either step through code or do data exploration and wrangle with what you are working with. This helped debug why a spatial join between the neighborhood dataframe and grocery stores dataframe was not working.
data = gpd.GeoDataFrame(data, geometry=gpd.points_from_xy(data.LATITUDE, data.LONGITUDE))
Looking at the neighborhood data, I realized that the Longitude came before Latitude. However, it makes sense because the Longitude is technically the horizontal access, hence the X-coordinate and the Latitude is the Y-coordinate. So switching that data allowed the spatial join to work as expected!
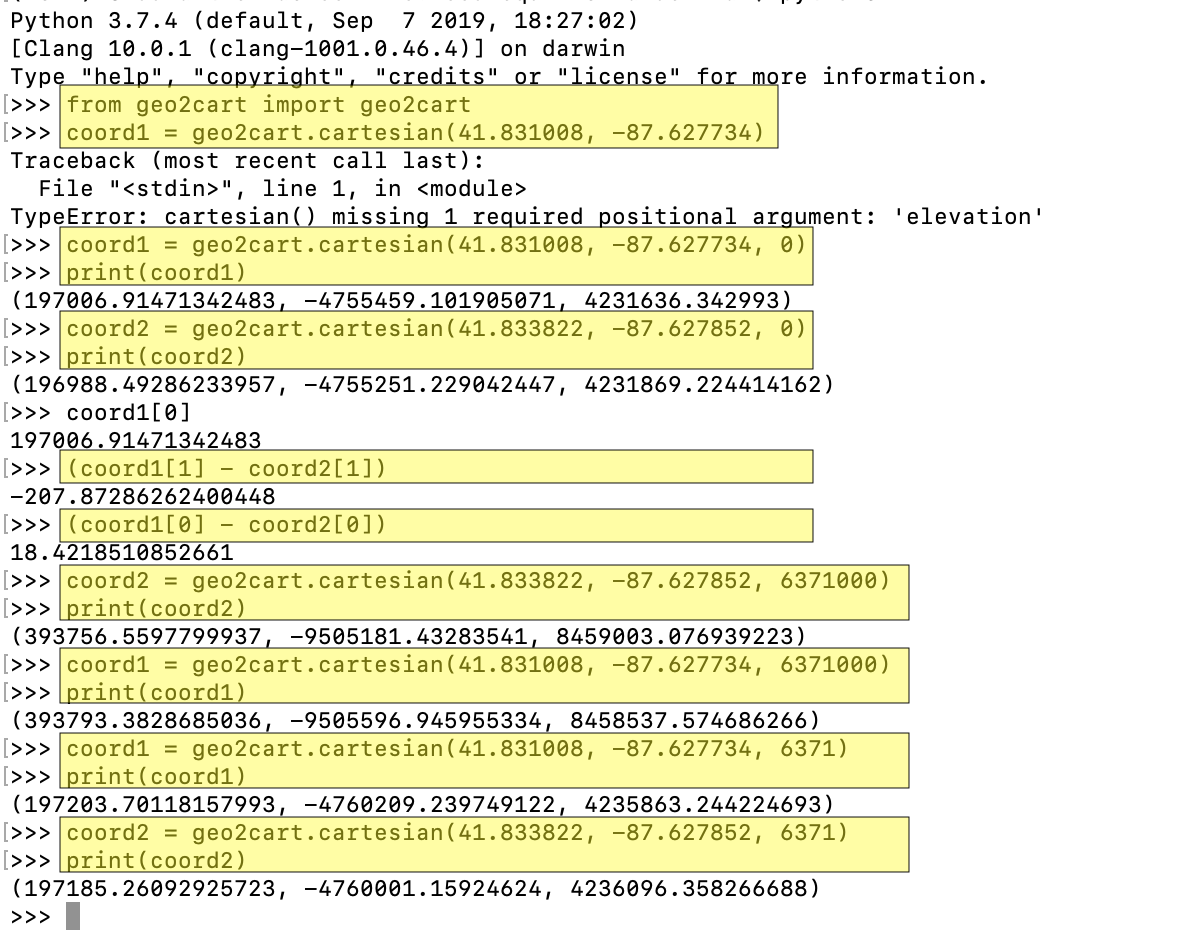
In an effort to not make this post too long, I want to explain how I used approximations for the coordinate projections. One of the major struggles I had was trying to code my own transformation and scouring the Internet to find something that converts latitude and longitude points to cartesian without having a height/altitude coordinate. After spending too much time researching, I decided to just try things out. So, I installed geo2cart which does the coordinate projections from geodetic data to cartesian coordinates. The first mistake I made was accidentally running Python 2 instead of Python 3.
Moving past that I experimented with values for the altitude. When I put the Earth’s approximate radius in meters it calculated the right distance. I realized I can sacrifice on accuracy for the projections because this is simply to form the grid cells, which means that the cartesian coordinates need to be in the right units (m -> km) and the placement relative to each other. This was an important lesson in just getting my hands dirty rather than wading through theory and not getting much done. Here is a screenshot of experimenting with different values of altitude and figuring out what the units need to be.
The Final Stretch of the ChiPy Mentorship Program
I can’t believe that there are only 3 more weeks left in the mentorship program. Over the last couple of months I’ve gotten much more comfortable with Python and it’s powerful libraries like Pandas. Through our different project nights, I’ve gotten see how object oriented programming, data science, and web development is done in Python. I’ve honestly never done such a wide variety of applications in such a short period of time. Since I am a college student, I am taking classes like Urban Planning Analysis and Probability/Statistics. In both of these classes, playing around in jupyter notebook allowed me to experiment and visualize different concepts.
I also got the chance to participate in the Dare Mighty Things hackathon last month where my team and I won the Best Voice Experience for Ulta Beauty using Google Cloud prize. This is the first hackathon I’ve won and where I felt confident in contributing with my team. Using Python to prototype an application and having a demo prepared in less than 24 hours means that we all had to contribute to the fullest of our abilities. I have never been able to accomplish this in Java or C++. In another case, I am also building a basic application with my Database Systems group using Flask and I was able to set up the backend+PostgreSQL for all three of our systems. Through the different projects I have been applying myself in and the mentorship I’ve received, it is becoming easier to spot errors in application and faster to fix them. I am immensely grateful for the mentorship and guidance Kevin has provided, and ChiPy for this opportunity to push myself.